|
Email: ruclhy1998[at]163.com Google Scholar Github Hi there! I am a Ph.D. Student at Renmin University of China, advised by Prof. Zhiwu Lu. I also work closely with Dr. Mingyu Ding at UC Berkeley and Prof. Bo Zhang at ZJU. Prior to the Ph.D. study, I received my B.E. degree in Computer Science from Renmin University of China in 2021. My research interests lie in multimodal foundation model and video understanding. |

|
|
|
|
Haoyu Lu*, Wen Liu*, Bo Zhang**, Bingxuan Wang, Kai Dong, Bo Liu, Jingxiang Sun, Tongzheng Ren, Zhuoshu Li, Hao Yang, Yaofeng Sun, Chengqi Deng, Hanwei Xu, Zhenda Xie, Chong Ruan (*Equal Contribution, **Project Lead) [Hugging Face] [PDF] [Code] [Demo] Introducing DeepSeek-VL, an open-source Vision-Language (VL) Model designed for real-world vision and language understanding applications. |
|
Yuqi Huo, Manli Zhang, Guangzhen Liu, Haoyu Lu, Yizhao Gao, Guoxing Yang, Jingyuan Wen, Heng Zhang, Baogui Xu, Weihao Zheng, Zongzheng Xi, Yueqian Yang, Anwen Hu, Jinming Zhao, Ruichen Li, Yida Zhao, Liang Zhang, Yuqing Song, Xin Hong, Wanqing Cui, Danyang Hou, Yingyan Li, Junyi Li, Peiyu Liu, Zheng Gong, Chuhao Jin, Yuchong Sun, Shizhe Chen, Zhiwu Lu, Zhicheng Dou, Qin Jin, Yanyan Lan, Wayne Xin Zhao, Ruihua Song, Ji-Rong Wen [PDF] [机器之心] Introducing WuDao-WenLan, a large-scale Chinese Vision-Language Pre-Training Model. |
|
|
|
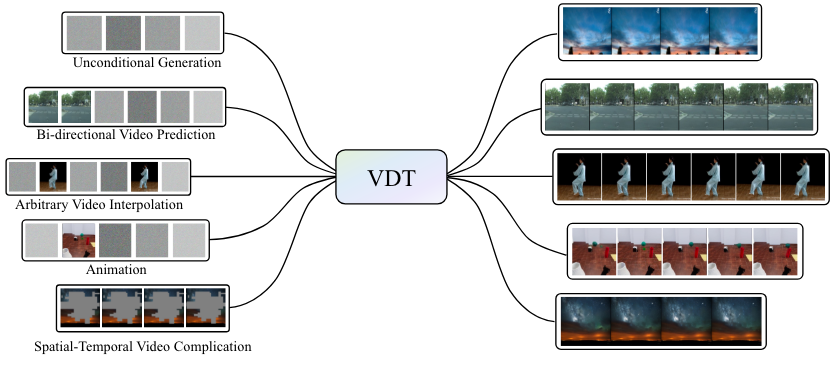
Haoyu Lu, Guoxing Yang, Nanyi Fei, Yuqi Huo, Zhiwu Lu, Ping Luo, Mingyu Ding ICLR2024 [Project] [PDF] [Code] [机器之心] We introduce Video Diffusion Transformer (VDT), which pioneers the use of transformers in diffusion-based video generation. |
|
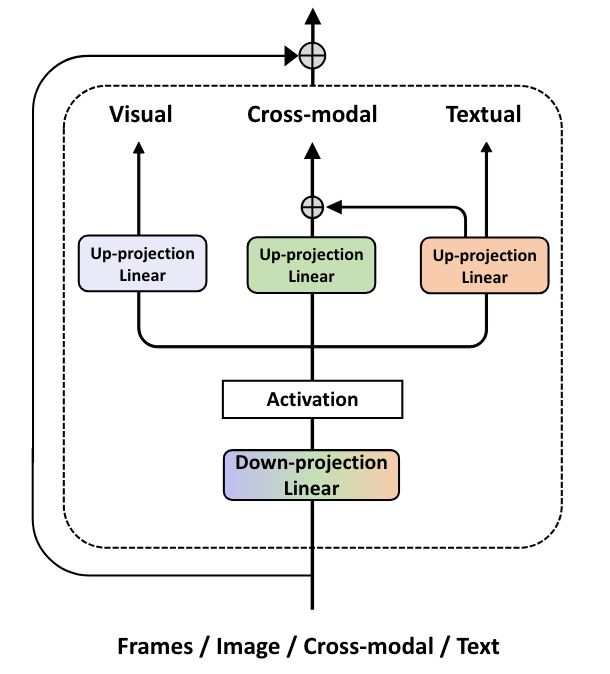
Haoyu Lu, Yuqi Huo, Guoxing Yang, Zhiwu Lu, Wei Zhan, Masayoshi Tomizuka, Mingyu Ding ICLR2024 [PDF] [Code] We propose UniAdapter, which unifies unimodal and multimodal adapters for parameter-efficient cross-modal adaptation on pre-trained vision-language models. |
|
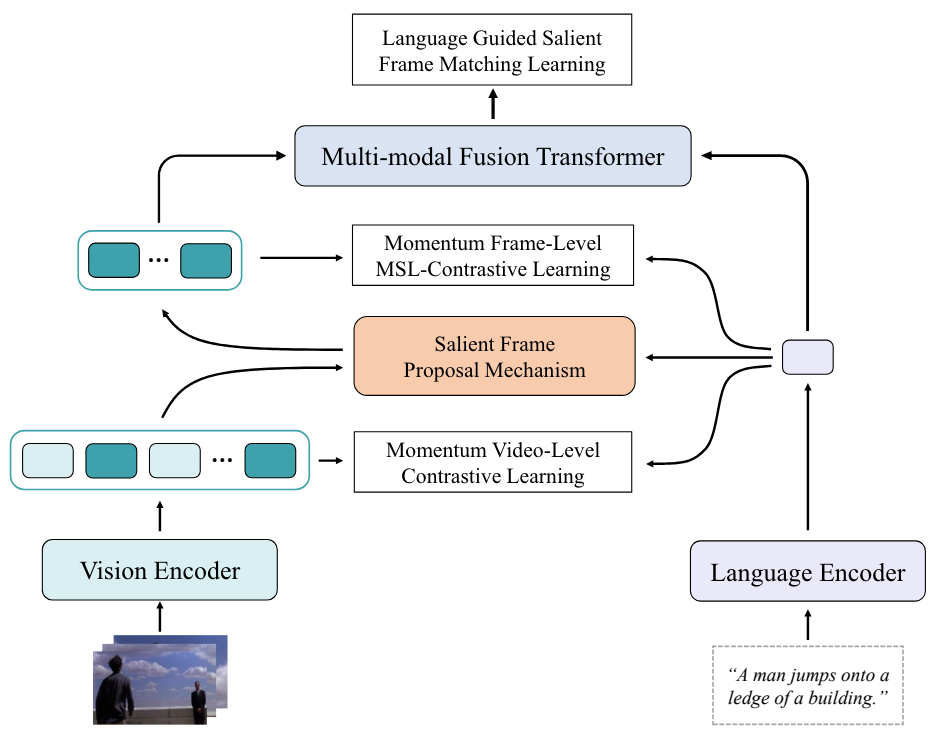
Haoyu Lu, Mingyu Ding, Nanyi Fei, Yuqi Huo, Zhiwu Lu NeurIPS2022, Spotlight [PDF] We propose Language-Guided Denoising Network (key-frame selection) for video-language modeling. |
|
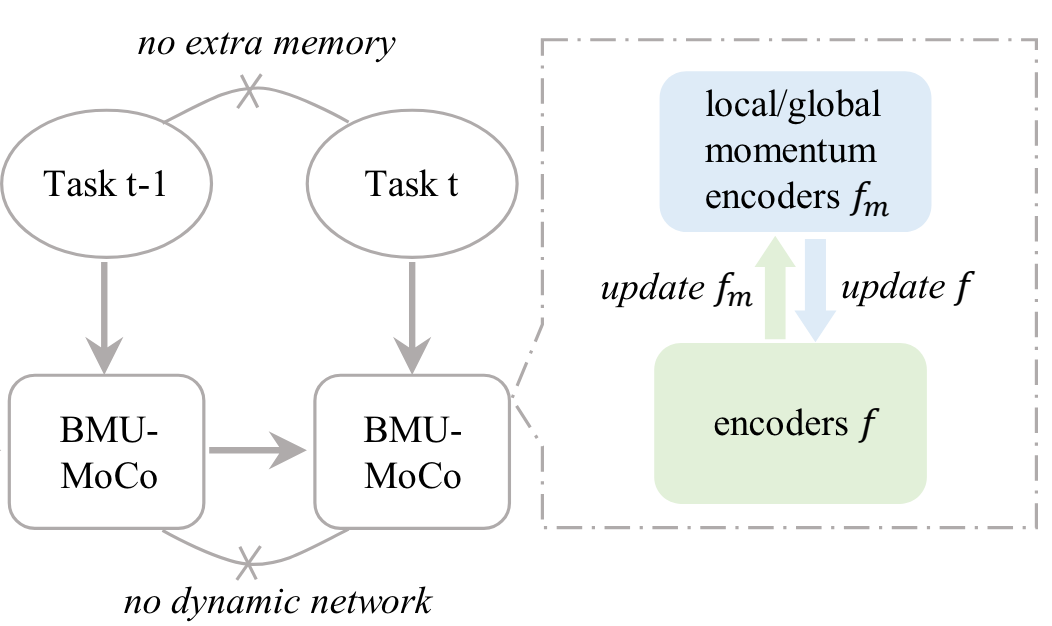
Yizhao Gao, Nanyi Fei, Haoyu Lu, Zhiwu Lu, Hao Jiang, Yijie Li, Zhao Cao NeurIPS2022, Spotlight [PDF] We propose a cross-modal MoCo-based continual learning algorithm with bidirectional momentum update (BMU). |
|
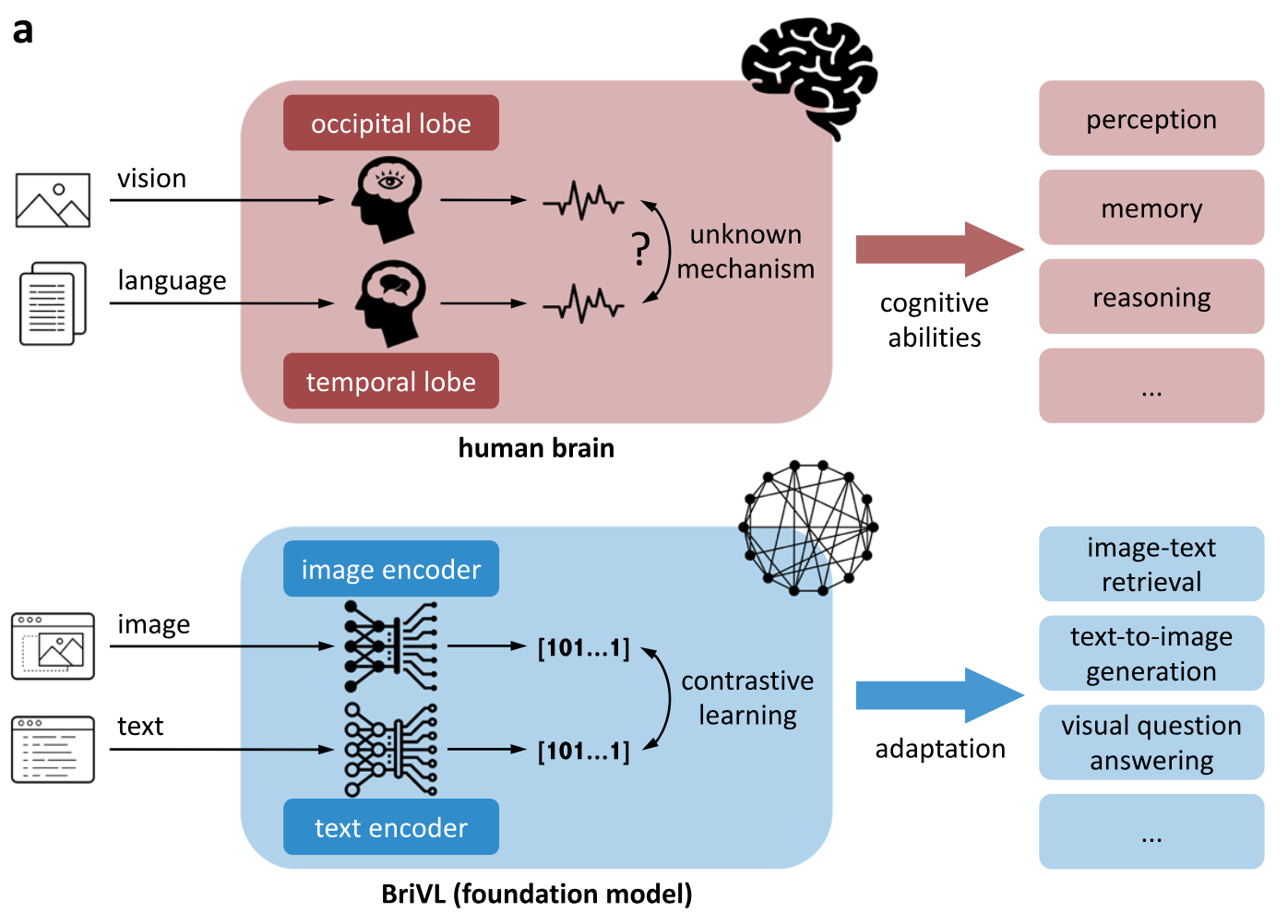
Nanyi Fei, Zhiwu Lu, Yizhao Gao, Guoxing Yang, Yuqi Huo, Jingyuan Wen, Haoyu Lu, Ruihua Song, Xin Gao, Tao Xiang, Hao Sun, Ji-Rong Wen Nature Communications [PDF] We develop a foundation model pre-trained with huge multimodal data, which can be quickly adapted for various downstream cognitive tasks. |
|
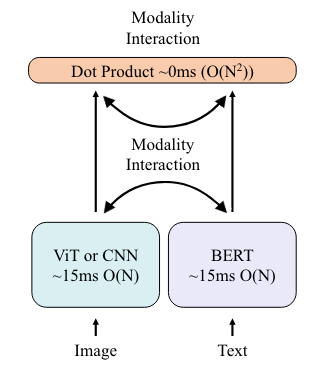
Haoyu Lu, Nanyi Fei, Yuqi Huo, Yizhao Gao, Zhiwu Lu, Ji-Rong Wen CVPR2022 [PDF] We propose COllaborative Two-Stream vision-language pre-training model (COTS) for cross-modal retrieval by enhancing cross-modal interaction. |
|
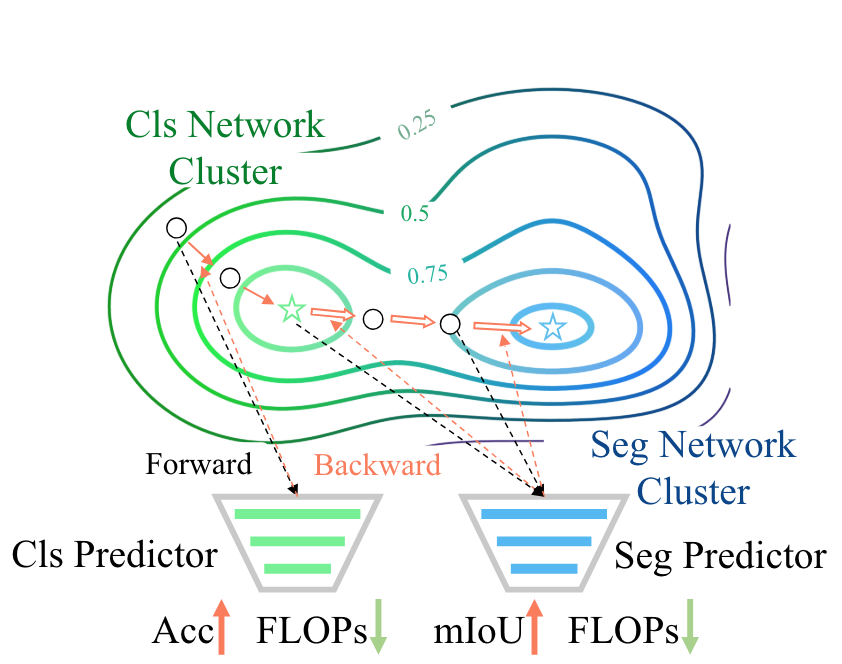
Mingyu Ding, Yuqi Huo, Haoyu Lu, Linjie Yang, Zhe Wang, Zhiwu Lu, Jingdong Wang, Ping Luo ICLR2022 [PDF] [Project] We explores how to design a single neural network capable of adapting to multiple heterogeneous vision tasks, such as image segmentation, 3D detection, and video recognition. |
|
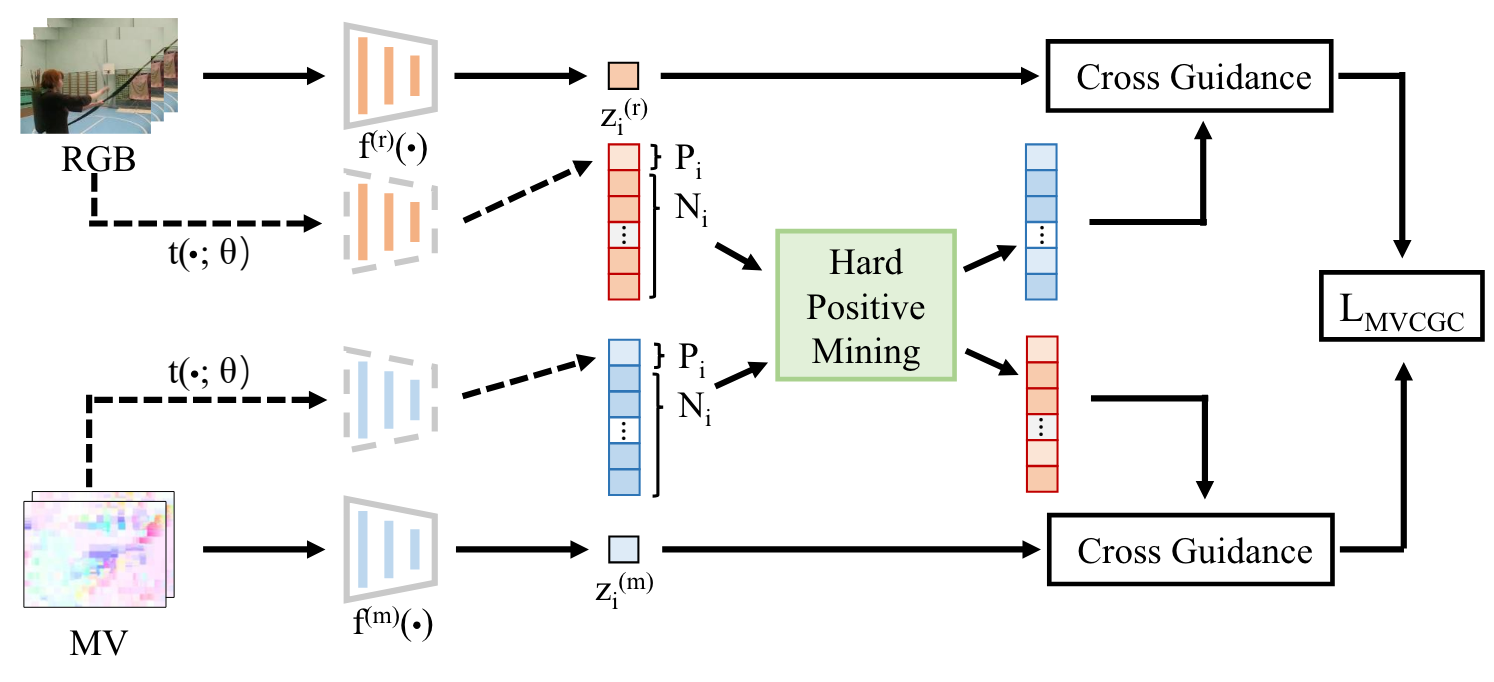
Yuqi Huo, Mingyu Ding, Haoyu Lu, Nanyi Fei, Zhiwu Lu, Ji-Rong Wen, Ping Luo NeurIPS2021 [PDF] We propose Motion Vector based Cross Guidance Contrastive learning for video self-supervised learning. |
|
Yuqi Huo, Mingyu Ding, Haoyu Lu, Zhiwu Lu, Tao Xiang, Ji-Rong Wen, Ziyuan Huang, Jianwen Jiang, Shiwei Zhang, Mingqian Tang, Songfang Huang, Ping Luo IJCAI2021 [PDF] We propose a pretext task for self-supervised video representation learning by exploiting spatiotemporal continuity in videos. |
|
The website template was adapted from Jingxiang Sun. |